Checkerberry db bietet die Möglichkeit den gesamten Datenbankinhalt oder den Inhalt ausgewählter Tabellen im Testdatenformat zu speichern.
Beispiel 2.38. Erstellen von Datenbank-Dumps
public void testAnything() throws Exception {
// Holen des Testhandlers.
DbTestHandler testHandler = getEnvironment().getTestHandler();
// Gesamte Datenbank in XML speichern.
testHandler.dumpDatabase("c:/temp/db-dump.xml");
// Tabelle USERS in XML speichern.
testHandler.dumpTable("c:/temp/users-dump.xml", "USERS");
// Tabellen ADDRESS und USERS in XML speichern.
testHandler.dumpTables("c:/temp/partial-dump.xml", "ADDRESS", "USERS");
}Das obige Beispiel zeigt die verschiedenen Möglichkeiten
Datenbankinhalte aus der Testmethode heraus zu speichern. Über die
Methode dumpDatabase wird der gesamte Datenbankinhalt
in einer XML-Datei gespeichert, während die Methode
dumpTable bzw. dumpTables nur eine
bzw. ausgewählte Tabelleninhalte in einer XML-Datei speichern. Die
XML-Dateien werden gemäß der konfigurierten DTD erstellt, sodass sie die
gleiche Struktur wie die Testdaten aufweisen.
Die folgenden Abbildungen verdeutlichen das Verhalten der
verschiedenen Dump-Methoden. In allen Abbildungen ist eine Datenbank
dargestellt, die für die drei Tabellen PIZZA,
TOPPING und USER jeweils einen
Eintrag enthalten.
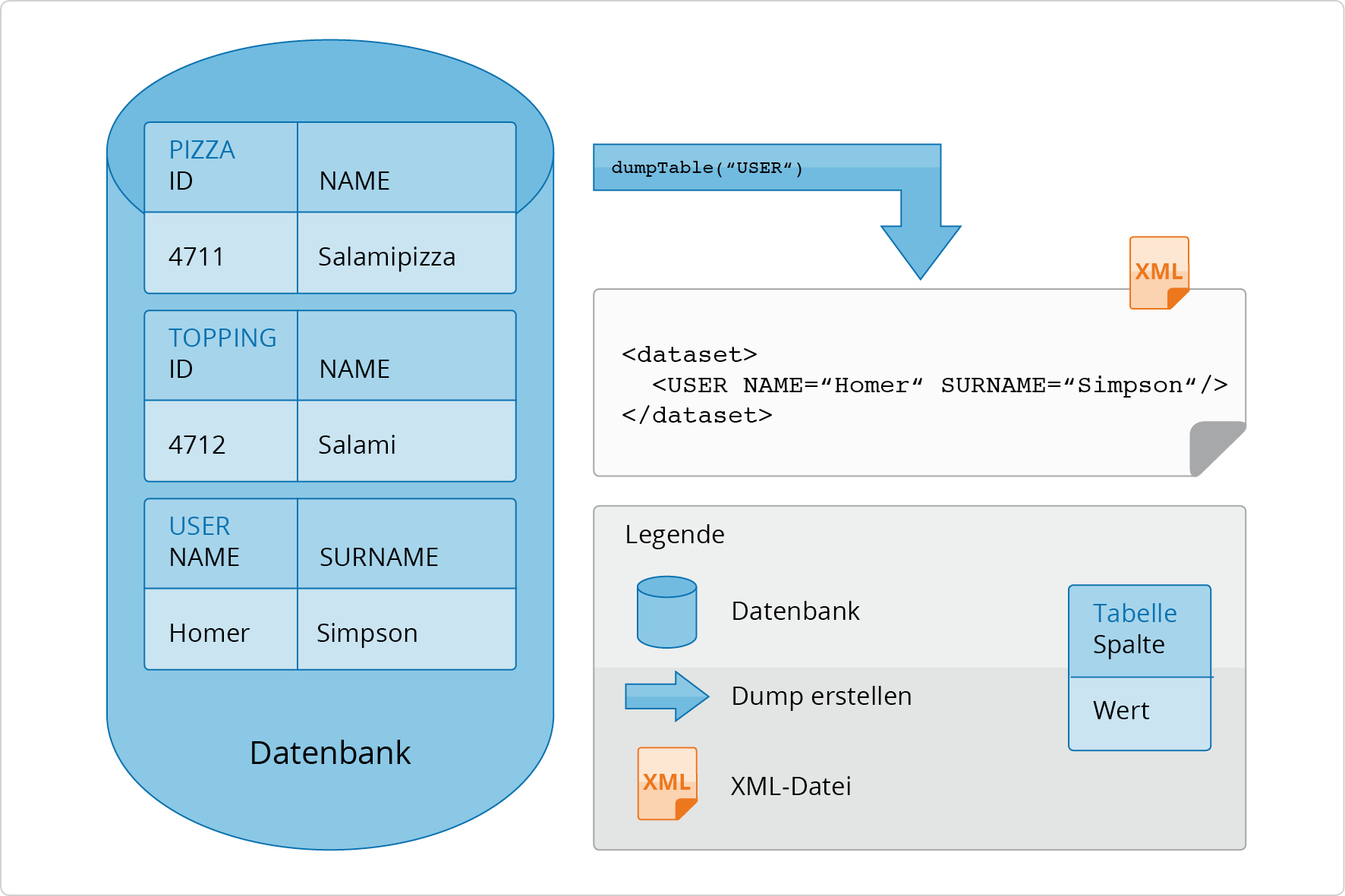
In Abbildung 2.20, „Datenbank-Dump für eine Tabelle“ wird die
Methode dumpTable für die Tabelle
USER aufgerufen. Das Ergebnis ist eine XML-Datei, die
nur den Inhalt der Tabelle USERS beinhaltet.
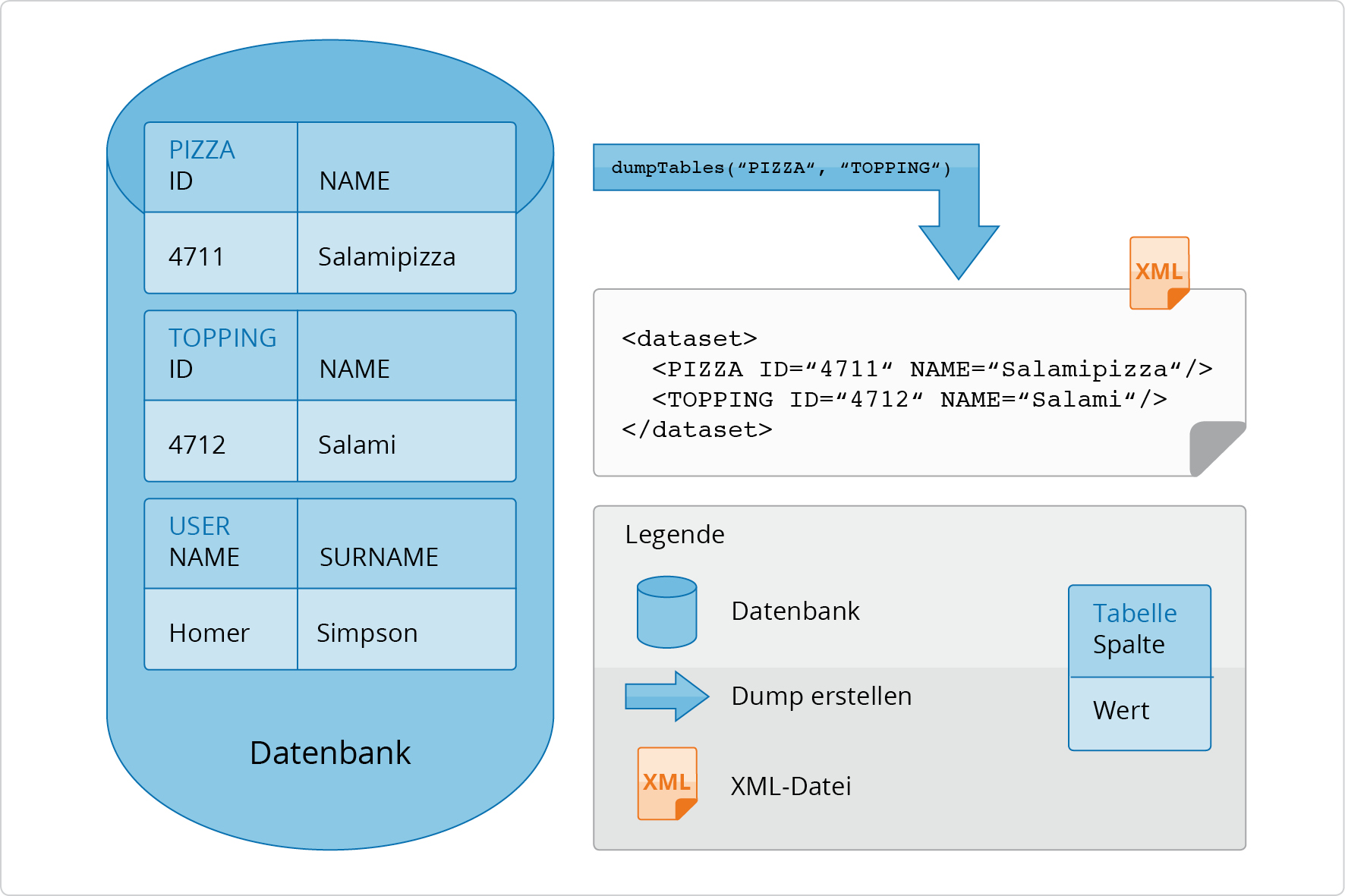
In Abbildung 2.21, „Datenbank-Dump für mehrere Tabellen“ wird die
Methode dumpTables für die Tabellen
PIZZA und TOPPING aufgerufen. Das
Ergebnis ist eine XML-Datei, die nur die Inhalte der Tabellen
PIZZA und TOPPING
beinhaltet.
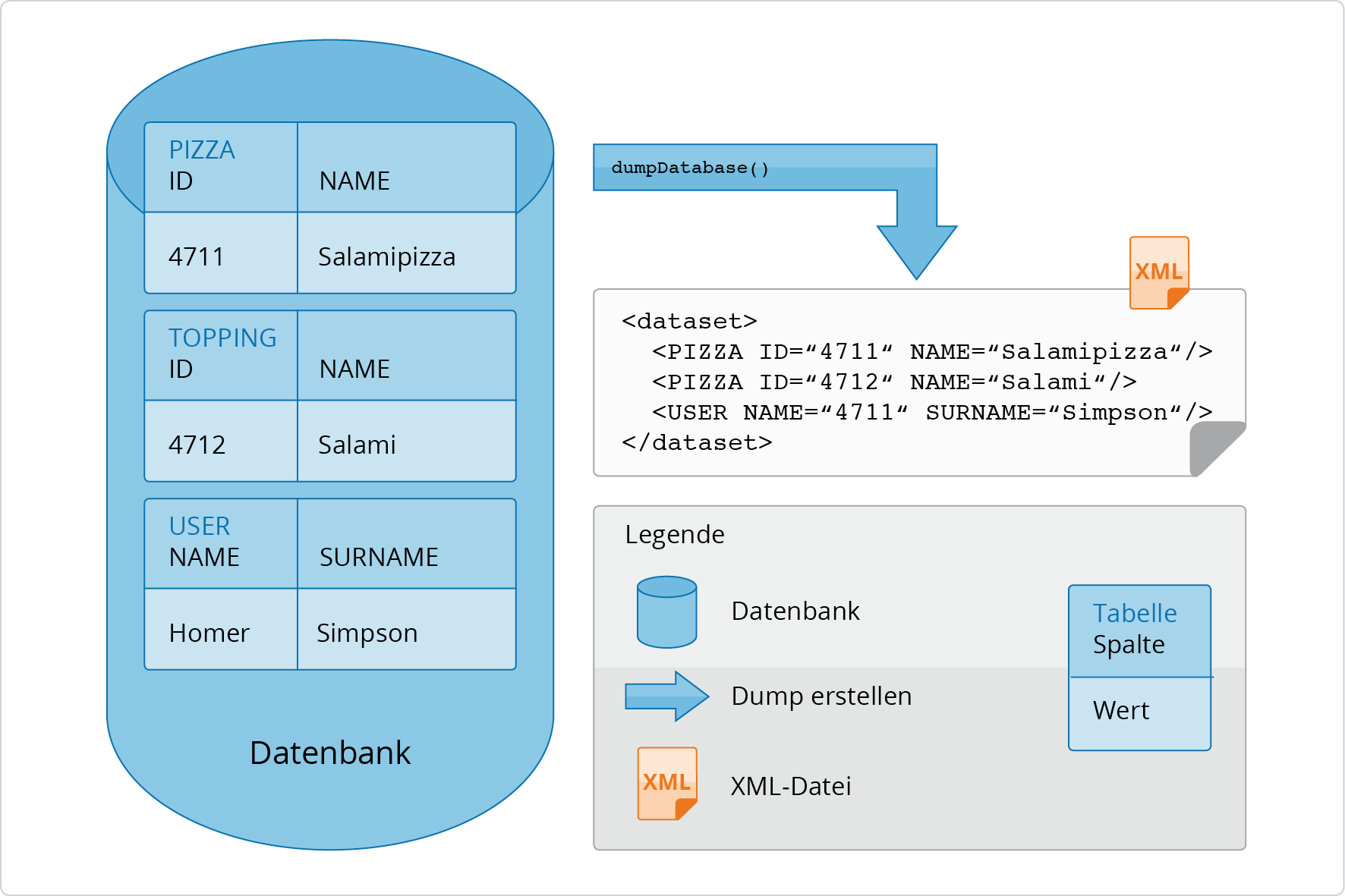
In Abbildung 2.22, „Datenbank-Dump für die gesamte Datenbank“ wird die
Methode dumpDatabase aufgerufen. Das Ergebnis ist
eine XML-Datei, die alle Tabelleninhalte der Datenbank beinhaltet. Die
XML-Datei enthält somit die Inhalte der Tabellen
USER, PIZZA und
TOPPING.
Möchte man den Datenbank-Dump übersichtlicher halten, bietet es
sich an, die cacheable Tabellen aus dem Datenbank-Dump auszuschließen.
Als cacheable werden ohnehin meistens Tabellen definiert, die Daten
enthalten, die während der Testdurchführung nicht geändert werden. Um
den Datenbank-Dump auf die nicht cacheable Tabellen zu beschränken, kann
die Methode dumpDatabase(String targetFile, boolean
excludeCacheableTables) verwendet werden, wobei der Boolean
excludeCacheableTables auf
true gesetzt werden muss.
Wenn die Daten zu umfangreich sind oder man bestimmte Daten für ein Testszenario auswählen möchte, kann man Daten anhand eines Regelwerks auswählen und in eine XML-Datei exportieren. Die Konsistenz der Daten wird dabei anhand von Fremdschlüsselinformationen sichergestellt.
Beispiel 2.39. Feingranulares Erstellen von Datenbank-Dumps
public void testAnything() throws Exception {
// Holen des Testhandlers.
DbTestHandler testHandler = getEnvironment().getTestHandler();
// Selektiert die Zeilen aus USERS mit ID=1
Recipe recipe = Recipe.with(Selection.table("USERS")
.where(TableConstraint.key("ID").eq().to(1))
.build())
.build();
// Selektiert alle Zeilen aus USERS mit ID>1 und ID<10
Recipe recipe = Recipe.with(Selection.table("USERS")
.where(TableConstraint.key("ID").type(Type.GT).to(1))
.where(TableConstraint.key("ID").type(Type.LT).to(10))
.build())
.build();
// Selektiert zusätzlich alle Zeilen aus LOCATIONS mit CityCode='HH'
Recipe recipe = Recipe.with(Selection.table("USERS")
.where(TableConstraint.key("ID").eq().to(1))
.build())
.and(Selection.table("LOCATIONS")
.where(TableConstraint.key("CityCode").eq().to("HH"))
.build())
.build();
// Daten aus Quelltabelle und alle referenzierten Daten in XML speichern.
testHandler.dumpTables("c:/temp/db-dump.xml", recipe);
}Zur Veranschaulichung der Funktionsweise gehen wir von folgenden Beispieldaten aus. In der Datenbank finden sich 3 Tabellen mit folgenden Werten:
Tabelle 2.3. Tabelle USERS
| ID | NAME | SURNAME | BIRTHDATE | WEIGHT |
|---|---|---|---|---|
1 | Homer | Simpson | 1946-09-16 | 80 |
2 | Marge | Simpson | 1950-09-16 | 60 |
Bei diesen Tabellen gibt es jeweils eine ForeignKey-Beziehung
von USERS und DISH auf
USERDISHREL (USERS.ID ->
USERDISHREL.ID und DISH.ID ->
USERDISHREL.DISH_ID) . Wenn nun ein Eintrag aus
USERS selektiert wird, benötigt man für konsistente
Daten auch alle Zeilen aus USERDISHREL die durch
die ForeignKey-Beziehung adressiert werden. Ausgehend von den aus
USERDISHREL selektierten Zeilen werden dann noch
alle Zeilen aus DISH benötigt, die durch die
ForeignKey-Beziehung zwischen DISH und
USERDISHREL adressiert werden.
Beispiel 2.40. Datenbankdump ausgehend von der USERS-Tabelle
// Selektiert die Zeilen aus USERS mit ID=1
Recipe recipe = Recipe.with(Selection.table("USERS")
.where(TableConstraint.key("ID").eq().to(1))
.build())
.build();
// Inhalt des Datenbank-Dump: <?xml version='1.0' encoding='UTF-8'?> <!DOCTYPE dataset PUBLIC ...> <dataset> <USERS ID="1" NAME="Homer" SURNAME="Simpson" BIRTHDATE="1946-09-16" WEIGHT="80.0"/> <USERDISHREL ID="1" DISH_ID="1"/> <DISH DISH_ID="1" DESCRIPTION="Donuts"/> </dataset>
Wird zusätzlich zum Eintrag aus USERS eine
weitere Selektion auf DISH definiert, dann benötigt
man auch alle Zeilen aus USERDISHREL und
USERS, die nach dem selben Schema durch die
ForeignKey-Beziehungen adressiert werden.
Beispiel 2.41. Datenbankdump ausgehend von der USERS- und der DISH-Tabelle
// Selektiert die Zeilen aus USERS mit ID=1
Recipe recipe = Recipe.with(Selection.table("USERS")
.where(TableConstraint.key("ID").eq().to(1))
.build())
.and(Selection.table("DISH")
.where(TableConstraint.key("DISH_ID").eq().to(1))
.build())
.build();
// Inhalt des Datenbank-Dump: <?xml version='1.0' encoding='UTF-8'?> <!DOCTYPE dataset PUBLIC ...> <dataset> <USERS ID="1" NAME="Homer" SURNAME="Simpson" BIRTHDATE="1946-09-16" WEIGHT="80.0"/> <USERS ID="2" NAME="Marge" SURNAME="Simpson" BIRTHDATE="1950-09-16" WEIGHT="60.0"/> <USERDISHREL ID="1" DISH_ID="1"/> <USERDISHREL ID="2" DISH_ID="1"/> <DISH DISH_ID="1" DESCRIPTION="Donuts"/> </dataset>
Wenn in der Datenbank Fremdschlüsselinformation (oder Primärschlüsselinformationen) fehlen, kann diese für den Export ergänzt werden.
Beispiel 2.42. Zusätzliche Definition von Primär- und ForeignKeys
// Definiert einen PrimaryKey mit der Spalte ID für USERDISHREL
Recipe recipe = Recipe.with(Selection.table("USERS")
.where(TableConstraint.key("ID").eq().to(1))
.build())
.primaryKey("USERDISHREL", "ID")
.build();
// Definiert eine ForeignKey-Beziehung von der Tabelle USERDISHREL
// und der Spalte DISH_ID
// auf Tabelle DISH und Spalte DISH_ID
Recipe recipe = Recipe.with(Selection.table("USERS")
.where(TableConstraint.key("ID").eq().to(1))
.build())
.foreignKey(ForeignKey.from("USERDISHREL", "DISH_ID")
.to("DISH", "DISH_ID"))
.build();
Wenn ein komplexes Domainmodell vorliegt, dass über sehr viele Fremdschlüsselbeziehungen verfügt, kann es vorkommen, dass beim Export der Daten das voreingestellte Limit für die Anzahl der Durchläufe überschritten wird. In diesem Fall kann man entweder die Auswahl eingrenzen oder das Limit erhöhen.
Die Anzahl der Durchläufe korreliert in einfachen Modellen mit der Anzahl der durch Fremdschlüssel referenzierten Tabellen. Für den einfachen Fall ist ein Wert der doppelt so hoch ist wie die Anzahl der im Export erwarteten Tabellen ein guter Startpunkt.
Beispiel 2.43. Erhöhen der maximalen Anzahl der Durchläufe
public class ConfigurationCallback implements DbConfigurationCallback {
public void configure(DbConfiguration configuration) {
configuration.setDumpRecipeMaxLoops(100);
}
}