Checkerberry db bietet eine Reihe von Features, die das Entwickeln von automatisierten Integrationstests auf mehreren Ebenen vereinfacht. Der Programmieraufwand wird minimiert, da grundlegende Aufgaben direkt von dem checkerberry test center übernommen werden. Dies umfasst zum Beispiel das Laden von initialen Testdaten, was bereits in der Setup-Phase des Tests erfolgt. Dadurch ist der Entwickler in der Lage, sich auf die fachlichen Aspekte in den Tests zu konzentrieren. Die Tests werden dadurch übersichtlich, verständlich und wartbar.
Um die Effizienz bei der Entwicklung von automatisierten Tests signifikant zu steigern, ist die reine Minimierung des Programmieraufwands nicht ausreichend. Ein Großteil des Aufwands bei der Entwicklung von automatisierten Tests entsteht bei der Erstellung der initialen und erwarteten Testdaten und vor allem bei der Fehleranalyse. Aus diesem Grund verfügt checkerberry db ebenfalls über Funktionen, die die Testdatenerstellung und die Fehleranalyse vereinfachen.
In checkerberry db werden die Testdaten in einem einfachen XML-Format definiert. Im Folgenden wird der Aufbau der Testdaten näher erläutert.
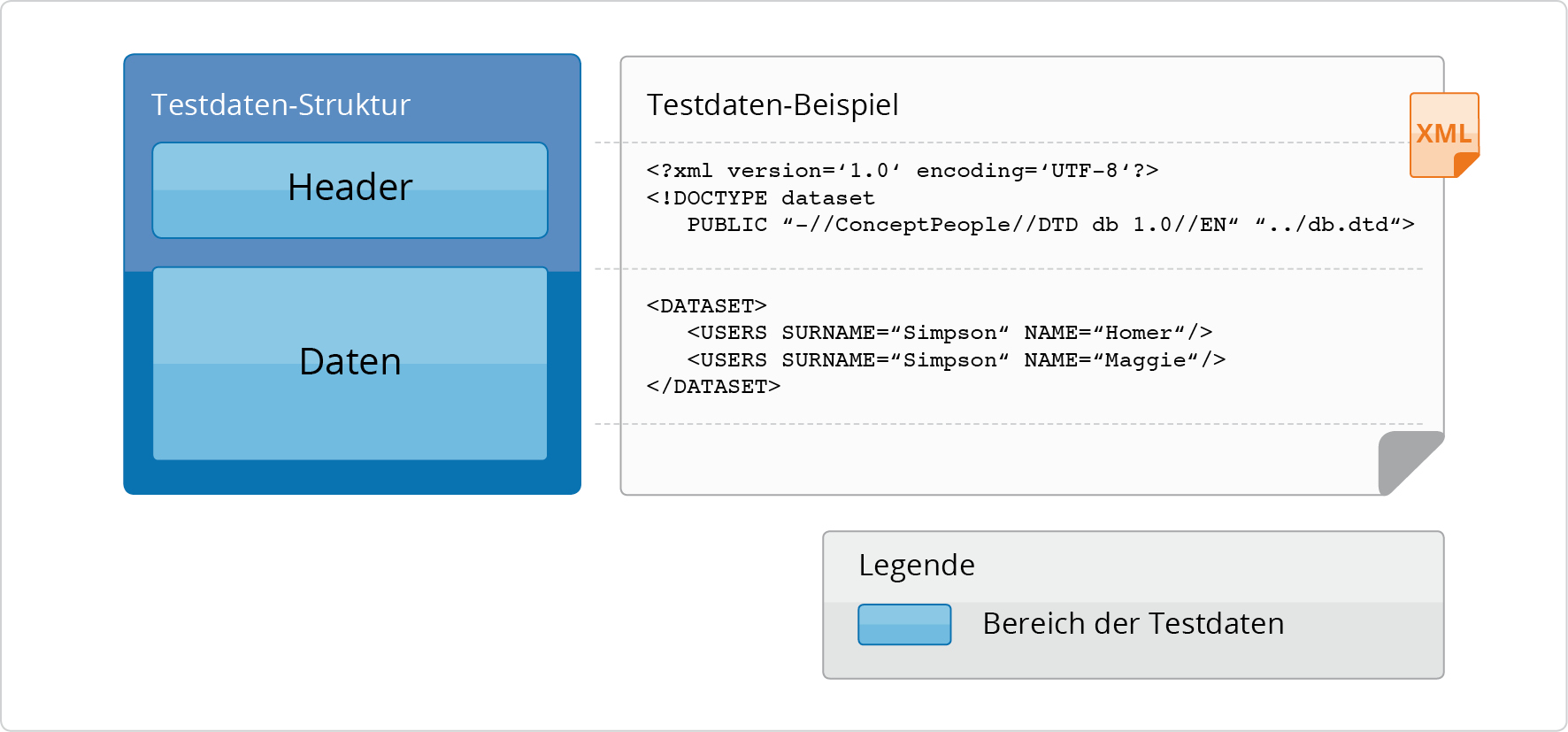
Wie in Abbildung 2.4, „Testdaten-Struktur“ dargestellt, bestehen Testdaten aus einem Header- und einem Datenbereich.
Der Header-Bereich besteht aus dem XML-Tag, der die XML-Version der Datei und das Encoding spezifiziert. Das DOCTYPE-Tag beschreibt, mittels welcher DTD checkerberry db die Korrektheit der Testdaten überprüfen kann.
Die DTD-Informationen werden in einer eigenständigen Datei
erwartet, die über einen öffentlichen Bezeichner ( public
identifier ) oder über einen expliziten Speicherort
angegeben werden kann. Der öffentliche Bezeichner (im Beispiel
"-//ConceptPeople//DTD db 1.0//EN" ) kann den
individuellen Bedürfnissen angepasst werden:
ConceptPeople ist die Angabe der zu
veröffentlichenden Person oder Institution und
db der Name der DTD, welcher mit dem Dateinamen
der DTD (ohne Endung) übereinstimmen sollte.
Der öffentliche Identifikator hat eine höhere Priorität als der
explizite Speicherort der Datei. Der explizite Speicherort wird
lediglich in den Entwicklungsumgebungen verwendet, wenn der
öffentliche Identifikator unbekannt ist. In der Eclipse IDE können
unter Windows->Preferences/XML/XML-Catalog
öffentliche Identifikatoren zu DTD-Dateien zugeordnet werden. Dieses
Vorgehen bietet sich insbesondere an, wenn mehrere Teilprojekte
dieselbe DTD verwenden, da dann die relative Angabe der zu
verwendenden DTD-Datei ohne die Überschreitung von Projektgrenzen z.B.
../../base-project/src/main/resources/de/conceptpeople/db.dtd
nicht möglich ist.
Checkerberry db verwendet ausschließlich den öffentlichen Identifikator für die Ermittlung der DTD. Die Zuordnung von öffentlichem Identifikator zu der entsprechenden Datei erfolgt während der Konfiguration von checkerberry db (siehe Abschnitt 2.4.1.4, „Konfiguration der Testdaten-DTD“). Da checkerberry db die DTD immer im Klassenpfad sucht, können verschiedene Teilprojekte dieselbe DTD verwenden. Die DTD kann dann in einem gemeinsamen Elternprojekt definiert werden, sodass alle Teilprojekte auf dieselbe DTD zugreifen können. Bei der Angabe eines relativen Dateinamens würde dies nicht funktionieren, was eine Duplizierung der DTD nach sich ziehen würde.
Der Datenbereich der initialen Testdaten beinhaltet die Informationen, die in die Datenbank eingespielt werden sollen. Bei den erwarteten Testdaten beinhaltet der Datenbereich die Informationen, die mit dem Datenbankinhalt verglichen werden sollen. In beiden Fällen enthält der Datenbereich somit Informationen, die sich auf den Datenbankinhalt beziehen.
Wie aus Abbildung 2.4, „Testdaten-Struktur“ hervorgeht, wird
der Datenbankinhalt innerhalb des
<dataset>-Tags spezifiziert. Die Syntax
der darunterliegenden Tags ergibt sich aus der Datenbankstruktur, die
über die DTD festgelegt wird. In dem Beispiel wird die Tabelle
USERS mit Daten gefüllt, und zwar in den
Spalten SURNAME und
NAME. Für jeden Datensatz wird ein eigenes
USERS-Tag verwendet.
Bei dem Einspielen von mehreren Tabellen in die Datenbank muss die Reihenfolge der einzuspielenden Tabellen berücksichtigt werden, um Constraint-Verletzungen in der Datenbank zu vermeiden. Diese Situation tritt dann auf, wenn ein Datensatz eingespielt wird, der einen anderen Datensatz referenziert. Ist der referenzierte Datensatz noch nicht in der Datenbank vorhanden, kommt es zu einem Fehler beim Einspielen.
Um die Eingabe der Testdaten optimal zu unterstützen, wird die korrekte Reihenfolge in der zugehörigen DTD festgelegt. Eventuelle Fehler können bereits bei der Validierung der XML-Datei gegen die DTD (zum Beispiel mit den Eclipse Validatoren) aufgedeckt werden.
Die Testdaten-DTD beschreibt die Struktur der Testdaten und
ergibt sich somit aus der Struktur der Datenbank. Die DTD definiert
eine Reihenfolge der enthaltenen Tabellen, definiert die Spalten jeder
Tabelle und speichert die Information, ob eine Spalte erforderlich ist
( not null ). Die Reihenfolge der Tabellen in der
DTD legt die Insert-Reihenfolge beim Einspielen der Testdaten fest.
Aus diesem Grund müssen die Abhängigkeiten der Tabellen untereinander
berücksichtigt werden, damit bei dem Einspielen der Testdaten keine
Constraint-Verletzungen in der Datenbank auftreten.
Beispiel 2.4. Beispiel Testdaten-DTD
<!-- Definition der enthaltenen Tabellen unter Berücksichtigung --> <!-- der Foreign-Key-Beziehungen. --> <!ELEMENT dataset ( USERS*, ADDRESS*, COUNTRY*)> <!-- Die Tabelle USERS hat keine Kind-Elemente (gilt generell für --> <!-- alle Tabellen). --> <!ELEMENT USERS EMPTY> <!-- Definition der Spalten der Tabelle USERS. --> <!ATTLIST USERS <!-- Not nullable Spalten werden durch #REQUIRED definiert. --> NAME CDATA #REQUIRED SURNAME CDATA #REQUIRED <!-- Nullable Spalten werden durch #IMPLIED definiert. --> BIRTHDATE CDATA #IMPLIED> …
Das dargestellte Code-Beispiel enthält eine beispielhafte DTD
für eine Testdaten-XML. Am Anfang der DTD wird definiert, welche
Elemente das Wurzelelement dataset beinhalten kann.
In dem konkreten Beispiel kann das dataset-Element
eine beliebige Anzahl von USERS-,
ADDRESS- und COUNTRY-Elementen
beinhalten. Da sich die DTD auf eine Datenbankstruktur bezieht,
handelt es sich bei den Kind-Elementen ( USERS,
ADDRESS und COUNTRY ) um Namen
der zugehörigen Datenbanktabellen.
Die Reihenfolge der Elemente wird durch die DTD fest vorgegeben.
Für eine XML-Datei, die der angegebenen DTD genügt, bedeutet dies,
dass als erstes alle USERS-Elemente, danach alle
ADDRESS-Elemente und zum Schluss alle
COUNTRY-Elemente angegeben werden müssen. Auf diese
Art und Weise wird auch die Reihenfolge festgelegt, in der die
Testdaten in die Datenbank eingespielt werden. Bei der Definition der
Reihenfolge müssen die Abhängigkeiten der Tabellen in der Datenbank
berücksichtigt werden. Anderenfalls kann das Einspielen der Testdaten
zu Constraint-Verletzungen führen, da ggf. ein eingefügter Datensatz
auf einen anderen Datensatz verweist, der noch nicht eingespielt
wurde.
Nach der Definition des dataset-Elements
erfolgt die Definition der Kind-Elemente. In dem konkreten Beispiel
wird das USERS-Element definiert. Zunächst wird
festgelegt, dass das USERS-Element keine
Kind-Elemente besitzt. Diese Angabe ist obligatorisch für alle
Tabellen-Definitionen, da die Informationen der Tabellen nicht über
XML-Kind-Elemente sondern über XML-Attribute angegeben werden. Für das
USERS-Element werden in der DTD die Attribute
NAME, SURNAME und
BIRTHDATE definiert. Es handelt sich dabei um die
Spaltennamen der USERS-Tabelle. Durch die
Eigenschaft #REQUIRED werden Pflichtfelder (
not null ) markiert. Optionale Spalten werden über
#IMPLIED markiert.
Die DTD wird von checkerberry db verwendet, um die zu vergleichenden Tabellen und Spalten zu ermitteln. Obwohl die Verwendung einer DTD unter DbUnit nicht vorgeschrieben ist, verwendet checkerberry db immer eine DTD. Wenn keine DTD vorhanden ist, fehlt DbUnit die Information, welche Spalten in einer Tabelle enthalten sind. Aus diesem Grund verwendet DbUnit die erste Zeile einer Tabelle in den Testdaten zur Ermittlung der vorhandenen Spalten. Dieses Vorgehen kann jedoch zu folgenden Problemen führen.
In DbUnit-Testdaten werden null-Werte dadurch
„dargestellt“, dass das entsprechende Spalten-Tag in den XML-Daten
fehlt. Ohne DTD kann DbUnit in der ersten Zeile einer Tabelle somit
nicht unterscheiden, ob eine Spalte fehlt oder ob der entsprechende
Wert null ist. Diese „Logik“ kann zu verwirrenden
Ergebnissen bei der Überprüfung der Testdaten führen. Aus diesem Grund
ist eine sinnvolle und nachvollziehbare Verwendung von DbUnit ohne DTD
kaum möglich.
Die DTD wird komplett automatisch erstellt und aktualisiert, sodass eine neue DTD nur noch manuell an die richtige Stelle des Ressource-Baumes des Testprojektes verschoben werden muss.
Die DTD-Erstellung aus großen Datenbanken ist sehr langsam, sodass man geänderte DTD-Dateien möglichst schnell in den Ressource-Baum übernehmen sollte. Insbesondere ist es nicht ratsam, die DTD bei jedem Testlauf neu aus der Datenbank generieren zu lassen.
In der Konfiguration wird die Verbindung des öffentlichen Identifikators zu der tatsächlichen DTD-Datei hergestellt.
Beispiel 2.5. Konfiguration der Testdaten-DTD
// Setzen der Zuordnung von öffentlichem Identifikator und der zugehörigen
// DTD-Datei. Die DTD-Datei wird dabei im Klassenpfad gesucht.
configuration.setDatabaseDtd("-//ConceptPeople//DTD sample-db 1.0//EN",
"de/conceptpeople/sample/sample-db.dtd");Das obige Beispiel zeigt die Konfiguration einer DTD in
checkerberry db. Durch den Aufruf der Methode
setDatabaseDtd wird checkerberry db die Zuordnung
zwischen öffentlichem Identifikator (-//ConceptPeople//DTD
sample-db 1.0//EN) und der DTD-Datei
(de/conceptpeople/sample/sample-db.dtd) mitgeteilt.
Die DTD-Datei wird dabei stets im Klassenpfad gesucht.
Beispiel 2.6. Referenzierung der DTD in den Testdaten.
<?xml version='1.0' encoding='UTF-8'?>
<!DOCTYPE dataset PUBLIC "-//ConceptPeople//DTD sample-db 1.0//EN" "…">Diese Konfiguration der DTD ist für die Verwendung von checkerberry db zwingend erforderlich.
Bei der Installation von checkerberry db wurde der Name der zu verwendenden Testdaten-DTD konfiguriert (siehe auch Abschnitt 2.4.1.4, „Konfiguration der Testdaten-DTD“). Die DTD-Datei existiert zu diesem Zeitpunkt in der Regel noch nicht. Die DTD kann jedoch schnell bei der Erstellung des ersten Testfalls aus der bestehenden Datenbank generiert werden.
Beispiel 2.7. Erzeugung einer DTD
DbTestHandler testHandler = getEnvironment().getTestHandler();
testHandler.createDtd("c:/tmp/sample-db.dtd");Mit den Zeilen weißt man checkerberry db an, eine neue DTD zu
erzeugen und unter dem gegebenen Dateinamen (hier
c:/tmp/sample-db.dtd) abzulegen. Zu diesem
Zweck wird die Datenbankstruktur aus der Datenbank ermittelt und die
gegenseitigen Abhängigkeiten der Tabellen berechnet. Mit Hilfe dieser
Informationen erzeugt checkerberry db die neue DTD.
Nach dem Erzeugen muss die DTD lediglich noch in den konfigurierten Pfad kopiert werden. Die beiden Zeilen zu Ihrer Erzeugung müssen aus dem Test wieder entfernt werden.
Bei einer Änderung der Datenbankstruktur muss auch die DTD angepasst werden. Ärgerlich kann es sein, wenn diese Anpassung vergessen wird und aus diesem Grund zahlreiche Tests in der Continuous Integration Umgebung fehlschlagen. Gerade bei großen Test-Suites mit einer langen Laufzeit kann dieser Informationsverlust schmerzhaft sein. Und natürlich passiert das immer zu den ungünstigsten Zeitpunkten.
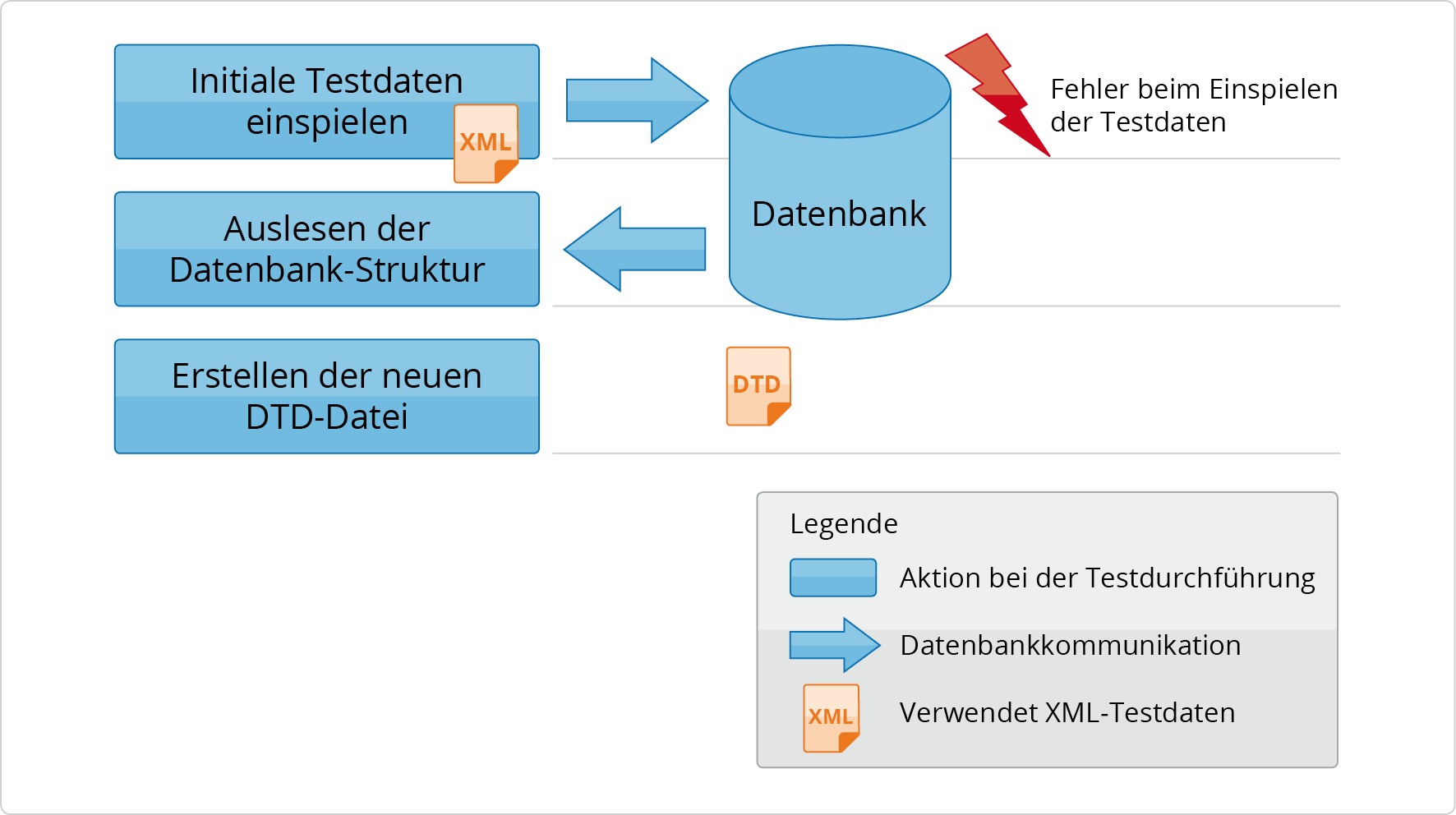
Abbildung 2.5, „Aktualisierung der DTD“ skizziert das Verhalten
von checkerberry db für den Fall, dass initiale Testdaten bei der
Durchführung eines Tests nicht eingespielt werden können. In der
Setup-Phase des durchzuführenden Tests versucht checkerberry db die
initialen Testdaten in die Datenbank einzuspielen. Dieser Versuch
schlägt fehl. Checkerberry db geht in dieser Situation davon aus, dass
die DTD nicht mehr die tatsächliche Datenbankstruktur beschreibt.
Checkerberry db ermittelt daraufhin die tatsächliche Datenbankstruktur
aus der Datenbank und erstellt anhand dieser Informationen eine neue
DTD. Diese wird im Klassenpfad unter demselben Pfad abgelegt wie die
alte DTD und lediglich mit dem Namenspräfix
„new-“ versehen. Alle nachfolgenden Tests
verwenden die neu generierte DTD.
Das beschriebene Vorgehen hat den Vorteil, dass kein kompletter nächtlicher Testlauf durch Nachlässigkeit verloren geht. Es wäre sinnlos, alle Tests mit der vorherigen DTD auszuführen, wenn davon ausgegangen wird, dass diese DTD fehlerhaft ist.
Der fehlgeschlagene Test, der die Aktualisierung der DTD hervorgerufen hat, wird nicht erneut ausgeführt. Er dient als Erinnerung, dass eine neue DTD erforderlich ist.
Die Erzeugung der DTD aus der Datenbank kann je nach Größe der Datenbank einige Minuten in Anspruch nehmen. Das Ziel sollte somit sein, dass die verwendete DTD-Datei immer den aktuellen Stand der Datenbank widerspiegelt, damit die Tests schnell ausgeführt werden. Insbesondere ist es nicht sinnvoll, die DTD vor jedem Testlauf oder vor jedem Test aus der Datenbank zu generieren. Zum einen verlängern sich auf diese Art und Weise die Ausführungszeiten. Zum anderen benötigen die Entwickler für die Erstellung der Testdaten eine aktuelle DTD, um die Korrektheit der Testdaten zu validieren. Darüber hinaus bieten viele IDEs durch die DTD eine Autovervollständigung bei der Eingabe der Testdaten an.
Die meisten Entwicklungsumgebungen unterstützen den Entwickler bei dem Editieren von XML-Dateien, wenn eine DTD definiert ist. Dazu gehört neben der Auto-Vervollständigung vor allem auch die syntaktische Validierung der Daten. Dies vereinfacht die Erstellung der Testdaten.

Abbildung 2.6, „Auto-Vervollständigung XML-Tag“ zeigt das Beispiel für eine
Auto-Vervollständigung in der Eclipse IDE. Die IDE schlägt dem
Benutzer die XML-Tags vor, die in die Testdaten eingefügt werden
können. Die Beispiel-Datenbank enthält nur die Tabelle
USERS. Zusätzlich können jedoch auch
INCLUDE-Einträge eingegeben werden.
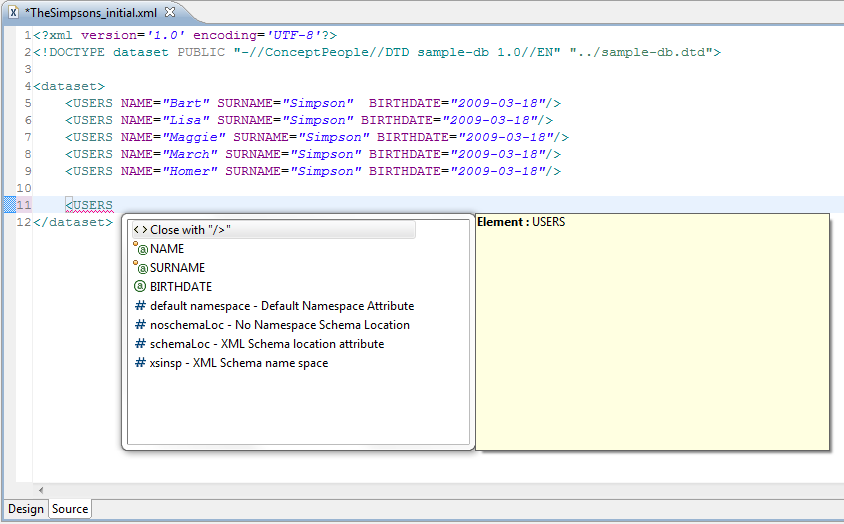
Abbildung 2.7, „Auto-Vervollständigung XML-Attribut“ zeigt die
Auto-Vervollständigung, nachdem ein XML-Tag ausgewählt wurde. In
diesem Fall bietet die IDE dem Benutzer die XML-Attribute
NAME, SURNAME und
BIRTHDATE zur Auswahl an. Es handelt sich dabei um
die Tabellenspalten der zugehörigen USERS-Tabelle.
Die XML-Attribute NAME und
SURNAME sind in dem Kontextmenü mit einem kleinen
Punkt markiert. Dieser Punkt wird zur Markierung von Pflichtfeldern
verwendet. Die Angaben NAME und
SURNAME müssen somit für jeden
USERS-Eintrag angegeben werden.
In dem ersten Beispiel wurden auch die XML-Tags
INCLUDE und EMPTY_TABLE durch
die Auto-Vervollständigung zur Auswahl angeboten, obwohl es sich nicht
um Tabellen aus der Datenbank handelt. Die Auto-Vervollständigung
orientiert sich an der DTD und die enthält die Beschreibung des
INCLUDE- und EMPTY_TABLE-Tags.
Die zusätzliche Beschreibung dieser beiden Tags wird durch
checkerberry db eingefügt, wenn die DTD aus den Datenbankinformationen
generiert wird.