In den meisten Datenbanken werden neben fachlichen Informationen auch technische Steuerinformationen oder sonstige Stammdaten gehalten. Diese Daten unterliegen nur sehr geringen oder gar keinen Änderungen. Dennoch beeinflussen sie das Verhalten der fachlichen Funktionen. Für die Entwicklung von automatisierten Tests mit checkerberry db bedeutet dies, dass diese Informationen Teil der Testdaten sein müssen.
Checkerberry db verfügt über einen Include-Mechanismus, um
Testdaten auszulagern und über eine Referenz in andere Testdatendateien
einzubinden. Zu diesem Zweck kann in den Testdaten das Tag
INCLUDE verwendet werden. Der Name des Tags ist
konfigurierbar (siehe Abschnitt 2.4.4.1, „Bezeichner der INCLUDE Tabelle anpassen“). Es hat die
folgenden Attribute:
FILE:Der Name der einzubindenden Testdatendatei.LOCATION:Der Ort wo die einzubindende Testdatendatei erwartet wird. Mögliche Ausprägungen sind:CLASSPATH:Sucht die Datei im KlassenpfadABSOLUTE:Die Angabe inFILEmuss ein absoluter Pfad sein.RELATIVE:In diesem Fall muss inFILEder relative Pfad zur einzubindenden Testdatendatei angegeben werden. Bei verschachtelt eingebundenen Testdaten wird der Pfad relativ zu der einbindenden Testdatendatei und nicht zu der ursprünglichen Testdatendatei angegeben.RELATIVEist der Default, wennLOCATIONnicht angegeben wird.
Beispiel 2.15. Einbinden von Testdaten über INCLUDE
<dataset> // Include einer Datei mit relativer Pfadangabe (relativ zu dieser Datei). <INCLUDE FILE="../TheSimpsons.xml"/> // Absolute Referenz auf eine Include-Datei <INCLUDE FILE="o:/groups/SharedProperties.xml" LOCATION="ABSOLUTE"/> // Angabe einer Include-Datei, die im Classpath gesucht wird. <INCLUDE FILE="de/conceptpeople/Properties.xml" LOCATION="CLASSPATH"/> <USERS NAME="Montgomery" SURNAME="Burns"/> <USERS NAME="Waylon" SURNAME="Smithers"/> </dataset>
Im Code-Beispiel werden die Dateien
TheSimpsons.xml,
SharedProperties.xml und
Properties.xml in die angegebenen Testdaten
eingebunden. Natürlich ist es möglich, Testdaten verschachtelt
einzubinden. Im obigen Beispiel wäre es somit denkbar, dass in der Datei
TheSimpsons.xml weitere Dateien wie z.B.
TheSimpsonsKids.xml und
TheSimpsonsGrownUps.xml eingebunden
werden.
Bevor checkerberry db die Daten in die Datenbank einspielt, werden die Daten aus den Include-Dateien eingelesen und gemäß der DTD sortiert. Danach werden die Daten in der ermittelten Reihenfolge eingespielt. Die folgenden Grafiken verdeutlichen diesen Sachverhalt.
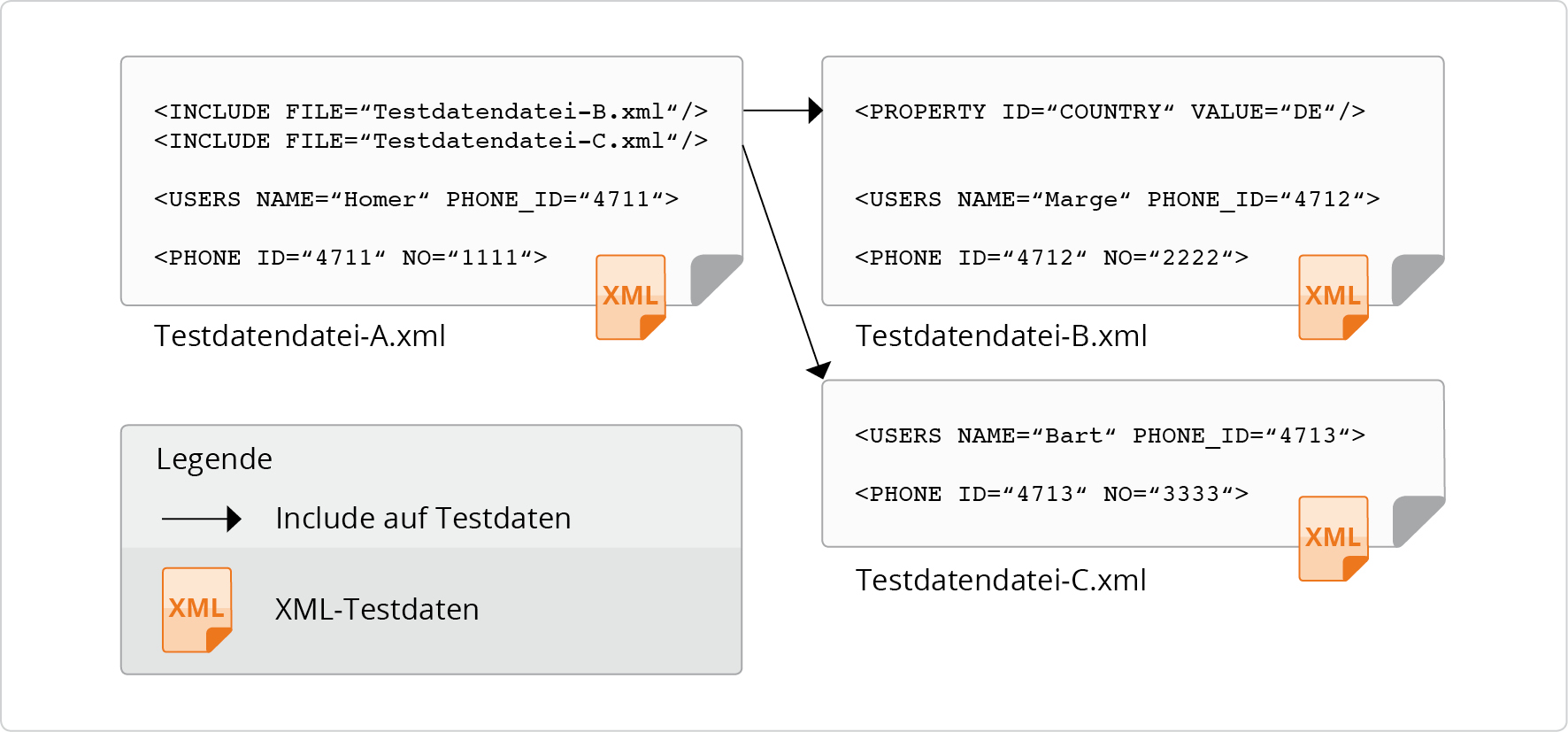
Die Abbildung zeigt den Datenteil von drei Testdatendateien. Die
Datei „Testdatendatei-A.xml“ inkludiert die Dateien
„Testdatendatei-B.xml“ und „Testdatendatei-C.xml“. Alle Testdatendateien
beinhalten zusätzlich Werte für die Tabellen
USERS und PHONE. Die
„Testdatendatei-B.xml“ enthält zusätzlich einen Eintrag für die Tabelle
PROPERTY.
Bei dem Einlesen einer Testdatendatei löst checkerberry db die inkludierten Referenzen auf und fügt die entsprechenden Daten ein. Die folgende Abbildung zeigt, welche Daten die „Testdatendatei-A.xml“ nach dem Einlesen enthält.
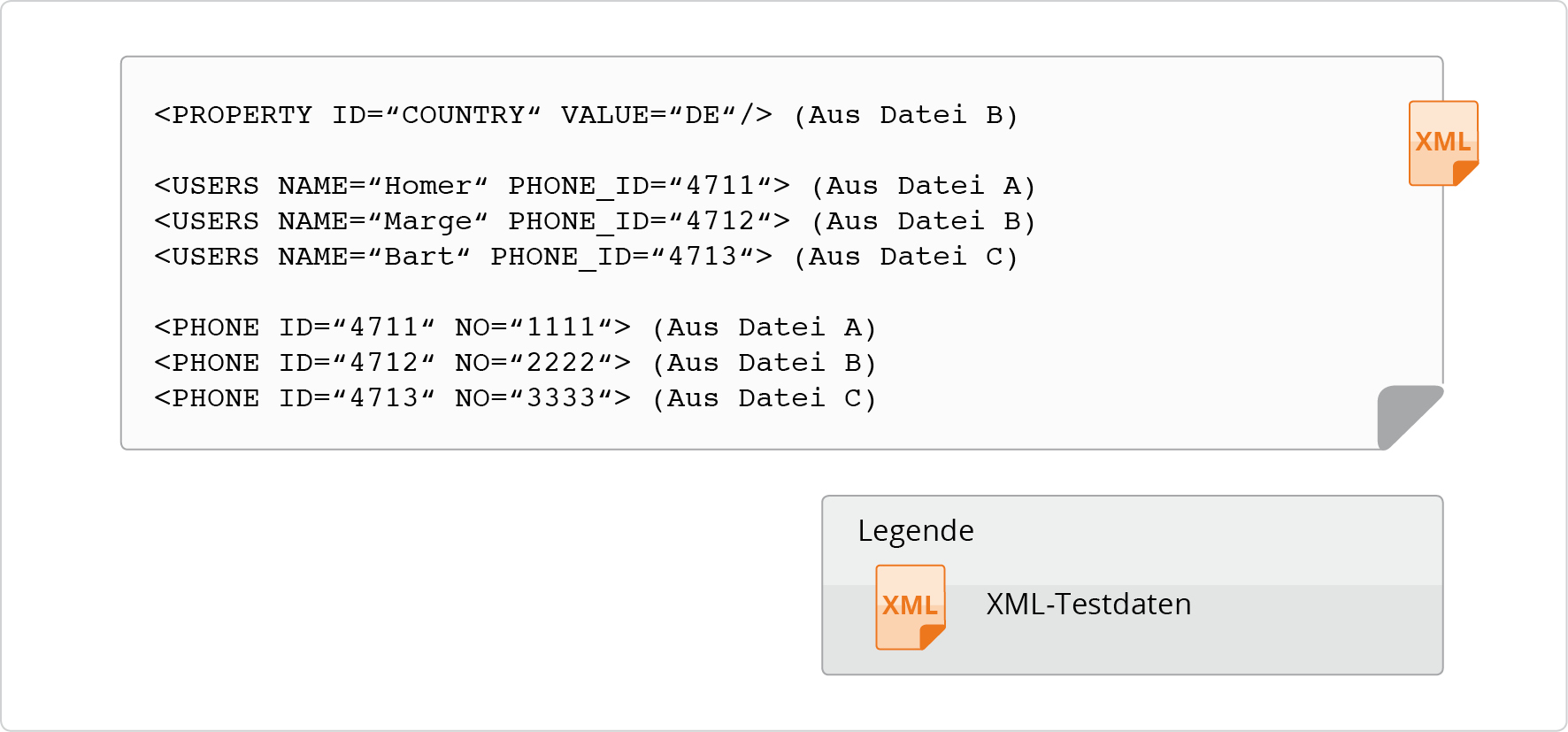
Die Datei „Testdatendatei-A.xml“ enthält nach dem Einlesen alle Informationen aus den drei Dateien „Testdatendatei-A.xml“, „Testdatendatei-B.xml“ und „Testdatendatei-C.xml“. Die Eingaben wurden dabei gemäß der DTD sortiert, sodass die korrekte Reihenfolge der Tabellen erhalten bleibt.
Beispiel 2.16. Include-Beispiel: Reihenfolge der Tabellen in der DTD
<!-- Reihenfolge der Tabellen --> <!ELEMENT dataset ( INCLUDE*, EMPTY_TABLE*, PROPERTY*, USERS*, PHONE*, …)> …
Die Struktur der Testdaten muss für alle Dateienidentisch sein,
d.h. alle müssen derselben DTD genügen. In dem Beispiel wird die oben
dargestellte DTD von den Testdaten verwendet. Die DTD definiert folgende
Reihenfolge der Tabellen: INCLUDE,
EMPTY_TABLE, PROPERTY,
USERS und PHONE. Es ist zu
beachten, dass die beiden Tabellen INCLUDE und
EMPTY_TABLE intern von checkerberry db verwendet
werden.
Das Include-Feature lässt sich sehr flexibel einsetzen. Oftmals
gibt es im konkreten Fall fachliche Standard-Konstellationen, die für
eine Reihe von Tests verwendet werden sollen. Auch in diesen Situationen
kann es sich anbieten, die Daten jeweils in eine eigene Datei
auszulagern z.B. CommonProperties.xml.
Des Weiteren können verschiedene Konfigurationen in eigenen
Dateien abgelegt werden, um diese dann je nach Bedarf einbinden zu
können z.B. PropertiesWebShopX.xml und
PropertiesWebShopY.xml.
Es kann vorkommen, dass checkerberry db in einer Umgebung
eingesetzt werden soll, in der bereits eine Datenbanktabelle mit dem
Namen „INCLUDE“ vorhanden ist. Damit der Name dieser Tabelle nicht mit
dem Namen des INCLUDE Tags kollidiert, kann dieser Bezeichner
konfiguriert werden. Mit der Methode
setIncludeTableName(String includeTableName)
wird der Default-Wert „INCLUDE“ überschrieben.
Beispiel 2.17, „Konfigurationseinstellungen für den Bezeichner der INCLUDE Tabelle“ enthält ein Beispiel für diese Konfigurationsmöglichkeit.
Beispiel 2.17. Konfigurationseinstellungen für den Bezeichner der INCLUDE Tabelle
public class ConfigurationCallback implements DbConfigurationCallback {
public void configure(DbConfiguration configuration) {
// Den Bezeichner des Tags von "INCLUDE" auf "INCLUDE_FILE" setzen.
configuration.setIncludeTableName("INCLUDE_FILE");
}
}