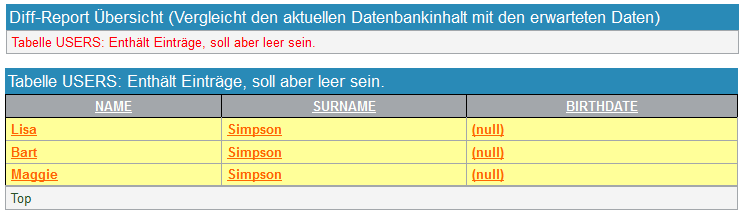
Stellvertretend für die verschiedenen Reports wird die Darstellung der Vergleichsergebnisse anhand eines Diff-Reports beschrieben. Die folgende Grafik zeigt einen möglichen Diff-Report.

Anhand des Diff-Reports erkennt man, dass die Datenbank aus
mehreren Tabellen mit den Namen USERS,
PIZZA, TOPPING,
PIZZA_TOPPING besteht. Die Werte der Spalten
werden in Grün dargestellt, wenn sie in den erwarteten Testdaten und
in dem tatsächlichen Datenbestand übereinstimmen. In dem obigen
Beispiel gibt es zwei Abweichungen in der Spalte
NAME der Tabelle
TOPPING. In der Zelle ist sowohl der erwartete
als auch der tatsächliche Datenbankwert angegeben. Aufgrund der
Abweichung ist der tatsächliche Wert Rot und der erwartete Wert Grün
dargestellt. Weitere Informationen zu Abweichungen liefern Tooltipps,
die angezeigt werden, wenn der Mauszeiger auf die entsprechende Zelle
zeigt.
Der Diff-Report ist besonders dann hilfreich, wenn die erwarteten Testdaten viele Abweichungen zum tatsächlichen Datenbestand aufweisen. Es ist sehr unwahrscheinlich, dass der fehlschlagende Test die wirkliche Ursache für den Fehler anzeigt. Stattdessen kann der Test einen Folgefehler anzeigen, den der Entwickler nicht erwartet hat. Durch den Diff-Report wird jedoch schnell klar, wo die tatsächliche Fehlerursache zu finden ist.
Der Diff-Report ist wie folgt gegliedert: In der Kopfzeile findet sich die Diff-Report Übersicht, in der Tabellen ohne Abweichung grün und Tabellen mit Abweichung rot markiert sind. Über einen Link kann man direkt zu der angegebenen Tabelle springen.
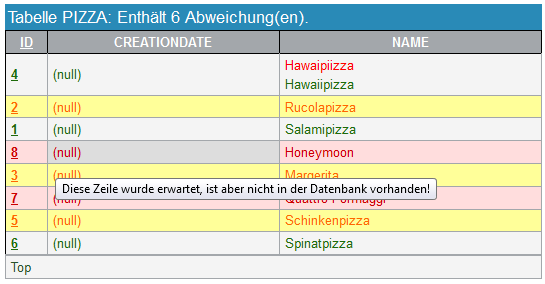
Anschließend werden alle nicht ausgeschlossenen Tabellen aufgelistet, die Daten enthalten oder für die Daten erwartet wurden. Die Daten werden auf Zeilen- und Werte-Ebene verglichen und die Unterschiede grafisch hervorgehoben (siehe Abbildung 2.30, „Tabelle mit Abweichungen“). Jede Zeile, die sowohl in der Datenbank als auch in den erwarteten Daten vorhanden ist, wird grau hinterlegt dargestellt. Eine Zeile, die in der Datenbank vorhanden ist, aber nicht erwartet wurde, ist gelb hinterlegt. Wurde eine Zeile erwartet, die nicht in der Datenbank vorhanden ist, wird sie rot hinterlegt dargestellt. Gibt es Abweichungen in einer Zeile, die sowohl in der Datenbank als auch in den erwarteten Daten vorhanden ist, so werden beide Werte innerhalb einer Zelle angezeigt. Dabei ist der tatsächliche Wert Rot und der erwartete Wert Grün eingefärbt.
Um die Zeilen der erwarteten und tatsächlichen Daten einander zuordnen zu können, werden Lookup-Keys benötigt (siehe Abschnitt 2.4.2, „Zuordnung von Testdaten und tatsächliche Daten“). Wenn keine Lookup-Keys für eine Tabelle definiert wurden, wird der Diff-Report für diese Tabellen trotzdem erstellt, indem alle Spalten als Lookup-Key verwendet werden. So kann der Diff-Report auch ohne die Definition von Lookup-Keys genutzt werden.
Die folgende Abbildung zeigt zwei Tabellen im Diff-Report, die ohne Lookup-Keys verglichen wurden.
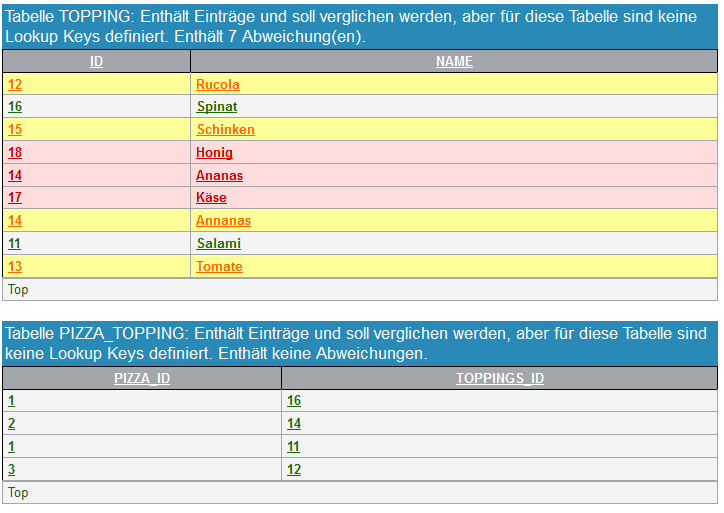
Weil der Diff-Report bei fehlenden Lookup-Keys alle Spalten als Lookup-Keys verwendet, werden geänderte Spalten zweimal aufgelistet: Als erwartete und als tatsächliche Spalte. Das ist z.B. bei ID 14 „Annanas“ / „Ananas“ der Fall.
Abbildung 2.32, „Tabelle nicht in der Datenbank vorhanden, obwohl sie erwartet wurde“ zeigt den Fall, dass eine ganze Tabelle in der Datenbank fehlt, obwohl sie erwartet wurde.
Tabellen, die nicht in den erwarteten Daten definiert wurden, werden nicht gegen den Datenbankinhalt geprüft. Sind für eine derartige Tabelle Einträge in der Datenbank vorhanden, wird die Tabelle in der Übersicht grün markiert (siehe Abbildung 2.33, „Tabelle soll nicht verglichen werden“).

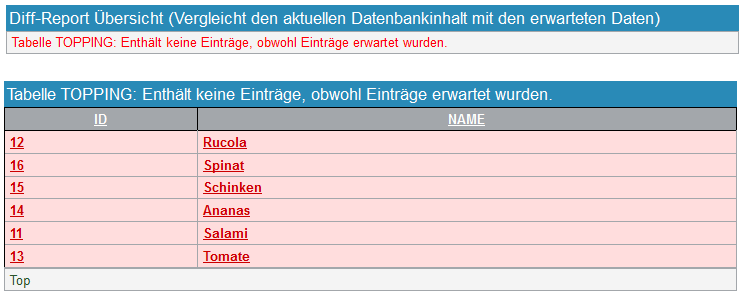
Es ist möglich, in den erwarteten Daten anzugeben, dass eine Tabelle leer sein soll (siehe Abschnitt 2.4.12, „Verwenden von leeren Tabellen“). Ist das der Fall und in der Datenbank sind für diese Tabelle Daten vorhanden, dann wird die Tabelle rot markiert (siehe Abbildung 2.34, „Tabelle wurde leer erwartet“).