Checkerberry db bietet die Möglichkeit allgemeine Testdaten in spezielle Testdaten einzubinden. Diese Möglichkeit erinnert an das DRY-Prinzip. Die Abkürzung DRY steht für „Don’t repeat yourself“ und beschreibt ein Prinzip aus der Software-Entwicklung, dass die Duplizierung von Source-Code untersagt. Der Source-Code ist so zu strukturieren, dass die Duplizierung von Code-Fragmenten nicht erforderlich ist. Diese Forderung ist ein wichtiger Baustein für die Entwicklung von wartbarem Source-Code.
Checkerberry db bietet technisch die Möglichkeit das DRY-Prinzip auch in den Testdaten umzusetzen. Davon sollte man jedoch maßvoll Gebrauch machen.
Java-Source-Code unterliegt klaren Regeln und lässt sich gut strukturieren. Die meisten Entwicklungsumgebungen bieten viele Möglichkeiten, den Source-Code zu analysieren, strukturiert darzustellen und unterstützen den Benutzer bei der Navigation zwischen den verschiedenen Klassen. Insbesondere lassen sich Referenzen der Klassen untereinander schnell ermitteln.
Bei der Bearbeitung von XML-Testdaten ist diese Tool-Unterstützung nicht vorhanden. Selbst die einfache Frage, in welchen Testdaten bestimmte Include-Dateien verwendet werden, ist nicht so leicht zu beantworten. Über eine einfache Suche findet man nur die Testdaten, die die Include-Datei direkt verwenden. Indirekte Verwendungen (Includes von Includes) findet man so nicht.
Das größere Problem stellt jedoch nicht die mangelnde Tool-Unterstützung dar, sondern der hohe Wiederverwendungsgrad. In den Testdaten gibt es immer ausgezeichnete Objekte, die in sehr vielen Tests verwendet werden können. Bei konsequenter Anwendung des DRY-Prinzips würden diese Daten ausgelagert und von vielen Tests referenziert werden. Die folgende Abbildung stellt das Problem dar.
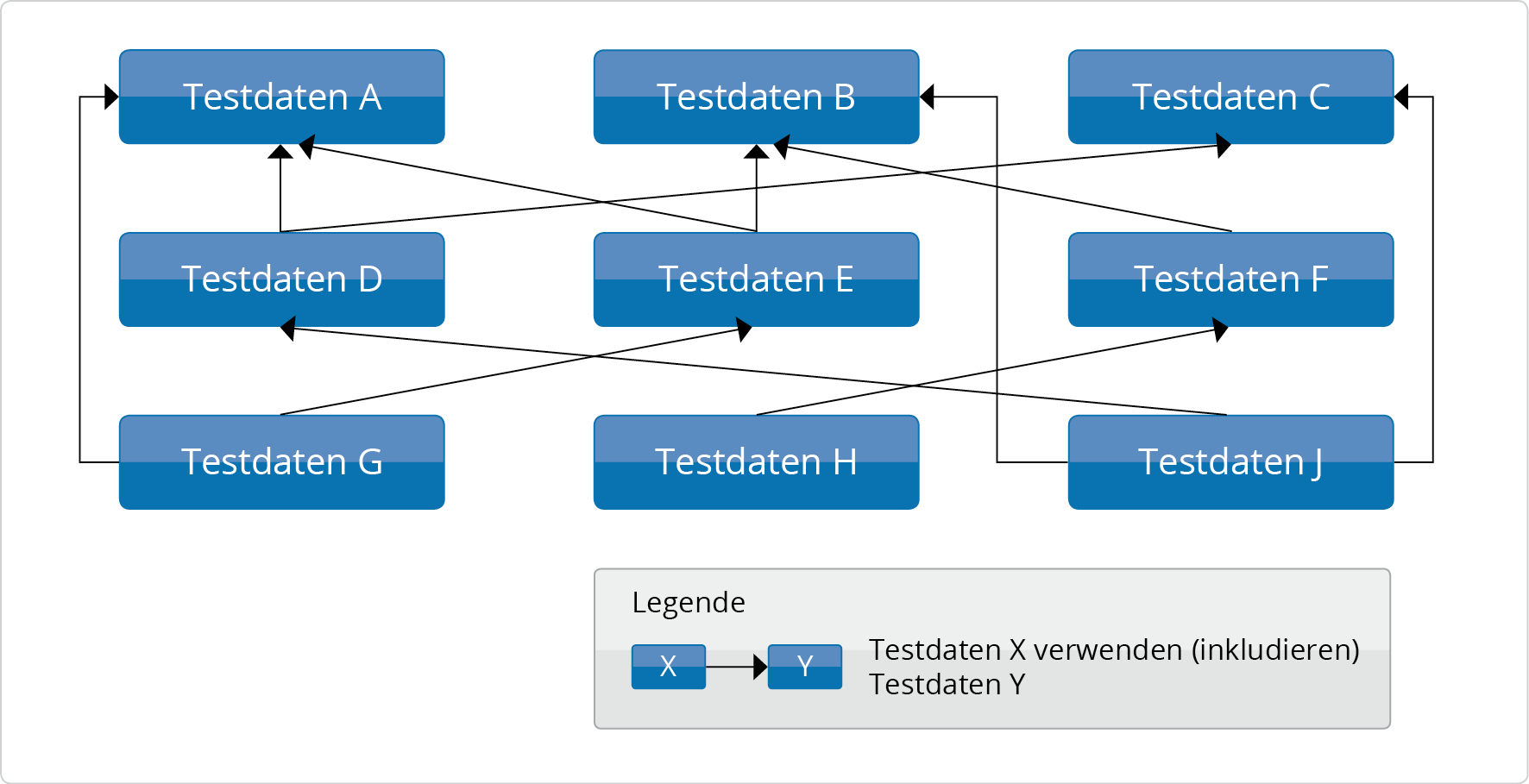
Die Abbildung zeigt mögliche Abhängigkeiten von Testdaten untereiander. Die Referenzen der Testdaten untereinander werden unüberschaubar. Dies führt zum einen dazu, dass auf den ersten Blick nicht ersichtlich ist, welche Testdaten für einen Test verwendet werden. Betrachtet man zum Beispiel die „Testdaten G“ aus der Abbildung, so werden dort die „Testdaten E“, „Testdaten A“ und „Testdaten B“ verwendet. Das Beispiel aus der Abbildung ist jedoch sehr klein. Bei einer konsequenten Umsetzung des DRY-Prinzips in einer realen Anwendung kann die Anzahl der inkludierten Testdaten für eine einzelne Testdatendatei schnell den zweistelligen Bereich erreichen.
Zum anderen ist die Wartbarkeit der Testdaten stark eingeschränkt, da der Entwickler nicht überblicken kann, was für Konsequenzen die Änderung von Testdaten hat. In der Abbildung werden die „Testdaten A“ von den „Testdaten G“ und „Testdaten J“ verwendet. Selbst in dieser einfachen Situation müssen bei einer Änderung der „Testdaten A“ die Auswirkungen auf die anderen Tests überprüft werden. Bei einer konsequenten Umsetzung des DRY-Prinzips würde die Wiederverwendung der Testdaten erheblich zunehmen. In dieser Situation können zentrale Testdaten dann im zwei- bis dreistelligen Bereich referenziert werden. Es könnte somit sein, dass die „Testdaten A“ nicht zweimal sondern 200 Mal referenziert werden. Das verhindert eine Änderung an den „Testdaten A“, da die Auswirkungen der Änderungen nicht überschaubar sind. Das Entstehen eines solchen Testdaten-Labyrinths sollte unbedingt vermieden werden.
Bei der Erstellung von Testdaten ist das DRY-Prinzip nicht geeignet. Es gibt eine Reihe von Daten, bei denen eine Auslagerung in separate Testdatendateien sinnvoll ist. Dies umfasst Stamm- oder Konfigurationsdaten sowie generelle fachliche Daten. Im Zweifel ist es besser Testdaten für den Preis der Wartbarkeit zu duplizieren.